Introduction to locally weighted linear regression (Loess)
What is Locally Weighted Linear Regression?
Locally weighted linear regression is a non-parametric algorithm, combines different types of regression models in a k-nearest-neighbor model. Locally weighted regression is called LOESS. LOESS combines much of the simplicity of linear least squares regression with the flexibility of nonlinear regression.
Locally Weighted regression is memory-based work that performs regression at a point using the training data that are local to a point. In Loess for each linear model we would like to suit, we discover some extent x and use that for fitting a local regression model.


Suppose If we want to evaluate the hypothesis of h at a certain local point x. For linear regression we do the following procedure:
- Fit to minimize
- Output
For locally weighted linear regression we will instead do the following:
- Fit to minimize
- Output
A fairly standard choice for the weights is the following bell-shaped function:
Note that this is just a bell-shaped curve, not a Gaussian probability function.
Here the weights depend upon the certain local point x at which we are evaluating linear regression The parameter controls how quickly the weight of a training example falls off with its distance the query point and is called the \textbf{bandwidth} parameter. In this case, increasing
increases the "width" of the bell shape curve and makes further points have more weight.
It is a vector, then this generalizes to be:

The Relationship of Kernel Regression and Locally Weighted Regression
LWR has more advantages than Keneral Regression. For a Planar local model, LWR is far better than Keneral regression since LWR will exactly produce a straight line as compared to keneral regression.Advantages
- Loess did not require any specification of a function to fit into a model of sample data.
- It is a supervised learning algorithm and extended form of linear regression
- It is non-parametric, and no training phase exists in this only testing.
- To avoid overfitting Loess allows us to put less care in selecting features in the data set.
- Low dimension supervised learning.
Disadvantages
- It requires a total training set to be to predict future predictions.
- As the size of the training set increases linearly parameters also get increases.
- Computationally intensive, as a regression model is computed for each point.
- Like other least square methods, prone to the effect of outliers in the data set.
Deriving the vectorized implementation
Consider the 1D case where and and are vectors of size . The cost function is a weighted version of the OLS regression, where the weights are defined by some kernel function
Canceling the terms, equating to zero, expanding and rearranging the terms:
Writing Eq. (1) and Eq. (2) in matrix form allows us to solve for
CODE :
Implementation in python
import matplotlib.pyplot as plt import pandas as pd import numpy as np from math import ceil from scipy import linalg from IPython.display import Image from IPython.display import display plt.style.use('seaborn-white') %matplotlib inline
import numpy as np from scipy import linalg #Defining the bell shaped kernel function - used for plotting later on def kernel_function(xi,x0,tau= .005): return np.exp( - (xi - x0)**2/(2*tau) ) def lowess_bell_shape_kern(x, y, tau = .005): """lowess_bell_shape_kern(x, y, tau = .005) -> yest Locally weighted regression: fits a nonparametric regression curve to a scatterplot. The arrays x and y contain an equal number of elements; each pair (x[i], y[i]) defines a data point in the scatterplot. The function returns the estimated (smooth) values of y. The kernel function is the bell shaped function with parameter tau. Larger tau will result in a smoother curve. """ m = len(x) yest = np.zeros(n) #Initializing all weights from the bell shape kernel function w = np.array([np.exp(- (x - x[i])**2/(2*tau)) for i in range(m)]) #Looping through all x-points for i in range(n): weights = w[:, i] b = np.array([np.sum(weights * y), np.sum(weights * y * x)]) A = np.array([[np.sum(weights), np.sum(weights * x)], [np.sum(weights * x), np.sum(weights * x * x)]]) theta = linalg.solve(A, b) yest[i] = theta[0] + theta[1] * x[i] return yest
Implementation in Python using span kernel and robustyfing
iterations
from math import ceil
import numpy as np
from scipy import linalg
def lowess_ag(x, y, f=2. / 3., iter=3):
"""lowess(x, y, f=2./3., iter=3) -> yest
Lowess smoother: Robust locally weighted regression.
The lowess function fits a nonparametric regression curve to a scatterplot.
The arrays x and y contain an equal number of elements; each pair
(x[i], y[i]) defines a data point in the scatterplot. The function returns
the estimated (smooth) values of y.
The smoothing span is given by f. A larger value for f will result in a
smoother curve. The number of robustifying iterations is given by iter. The
function will run faster with a smaller number of iterations.
"""
n = len(x)
r = int(ceil(f * n))
h = [np.sort(np.abs(x - x[i]))[r] for i in range(n)]
w = np.clip(np.abs((x[:, None] - x[None, :]) / h), 0.0, 1.0)
w = (1 - w ** 3) ** 3
yest = np.zeros(n)
delta = np.ones(n)
for iteration in range(iter):
for i in range(n):
weights = delta * w[:, i]
b = np.array([np.sum(weights * y), np.sum(weights * y * x)])
A = np.array([[np.sum(weights), np.sum(weights * x)],
[np.sum(weights * x), np.sum(weights * x * x)]])
beta = linalg.solve(A, b)
yest[i] = beta[0] + beta[1] * x[i]
residuals = y - yest
s = np.median(np.abs(residuals))
delta = np.clip(residuals / (6.0 * s), -1, 1)
delta = (1 - delta ** 2) ** 2
return yest
f = 0.25
yest = lowess_ag(x, y, f=f, iter=3)
yest_bell = lowess_bell_shape_kern(x,y)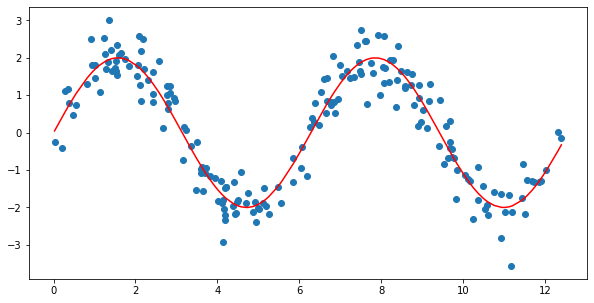
REFERENCES:
- https://www.olamilekanwahab.com/blog/2018/01/30/locally-weighted-regression/
- https://gerardnico.com/data_mining/local_regression
- https://www.ri.cmu.edu/pub_files/pub1/atkeson_c_g_1997_1/atkeson_c_g_1997_1.pdf
- By the Locally weighted regression, higher flexibility will obtained and desirable properties like smoothness and statistical analyzability will be retained.
- Locally weighted learning is increasing rapidly in the machine learning community.
- It minimizes the computational cost of training and new data points will store in the memory.
- You must be clear while considering the learning algorithm since every algorithm has its own advantages.



